Visualizing data loaders to diagnose deep learning pipelines
Have you wondered why some of your training scripts halt every n batches where n is the number of loader processes? This likely means your pipeline is bottlenecked by data loading time, as shown in the following animation:
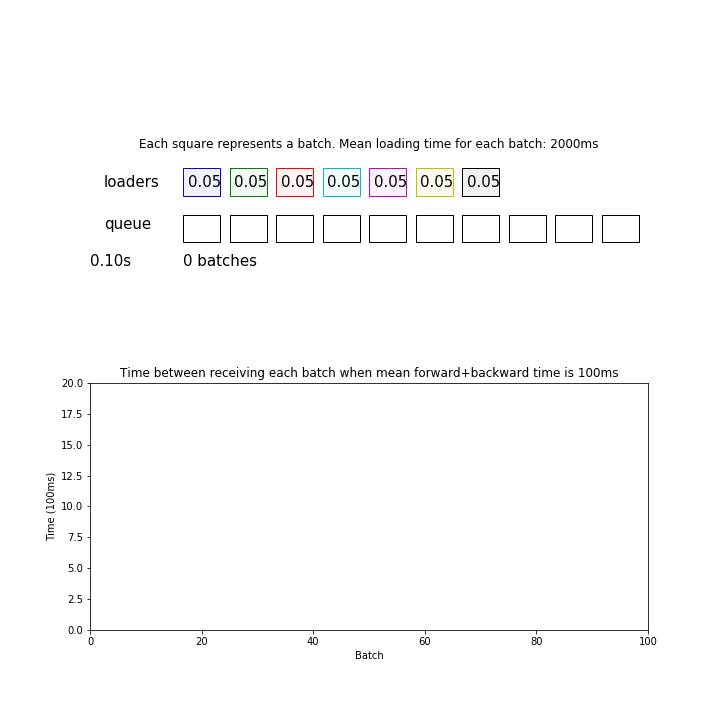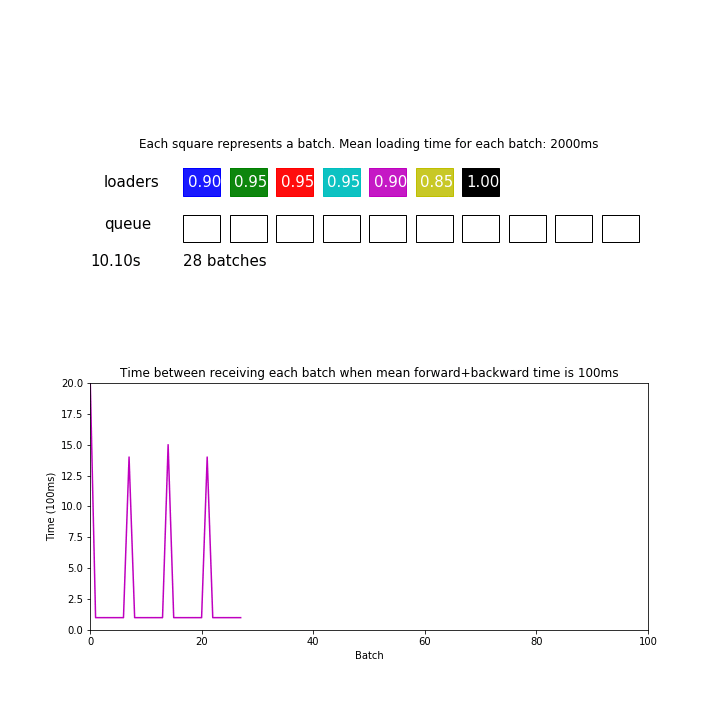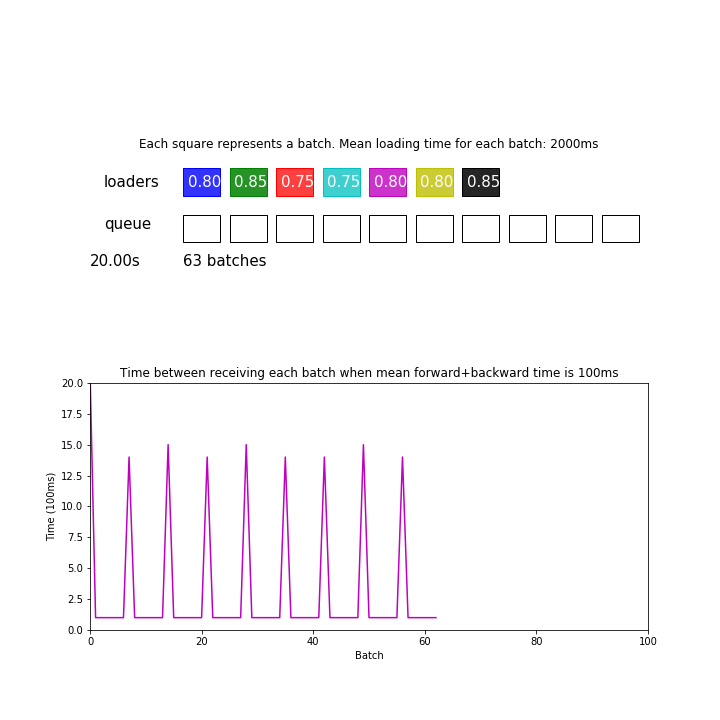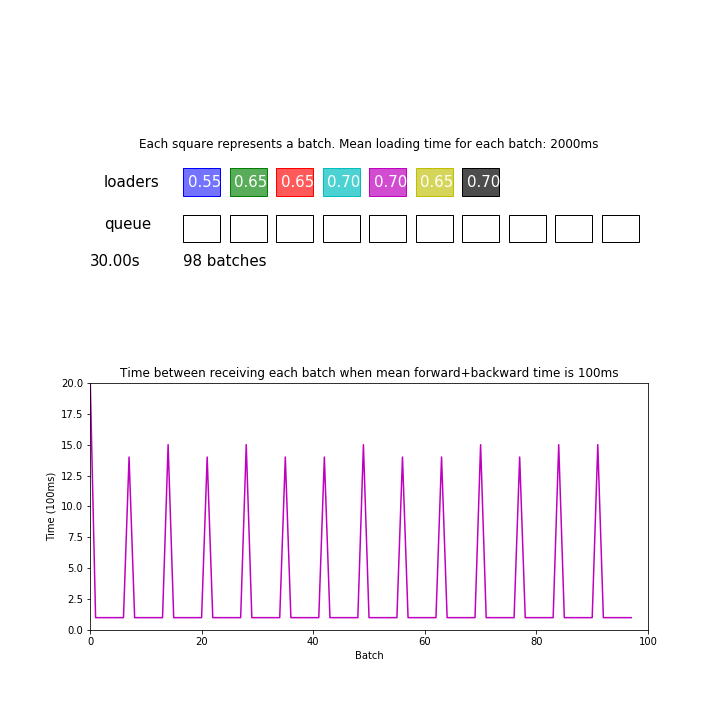
In the animation above, mean loading time for each batch is 2 seconds, and there are 7 processes but forward+backward pass for each batch only takes 100ms. We are ignoring the time it takes to send data between processes and devices for simplicity.
Since 2 seconds / 7 = 286 ms is greater than 100 ms, the model is consuming batches faster than the loaders can give. This pipeline processed 98 batches during the first 30 seconds.
If we succeed in decreasing the data loading time by using more efficient augmentation functions and/or saving files in different formats, we will no longer observe such abrupt stopping of training every n batches, as shown in the following animation:
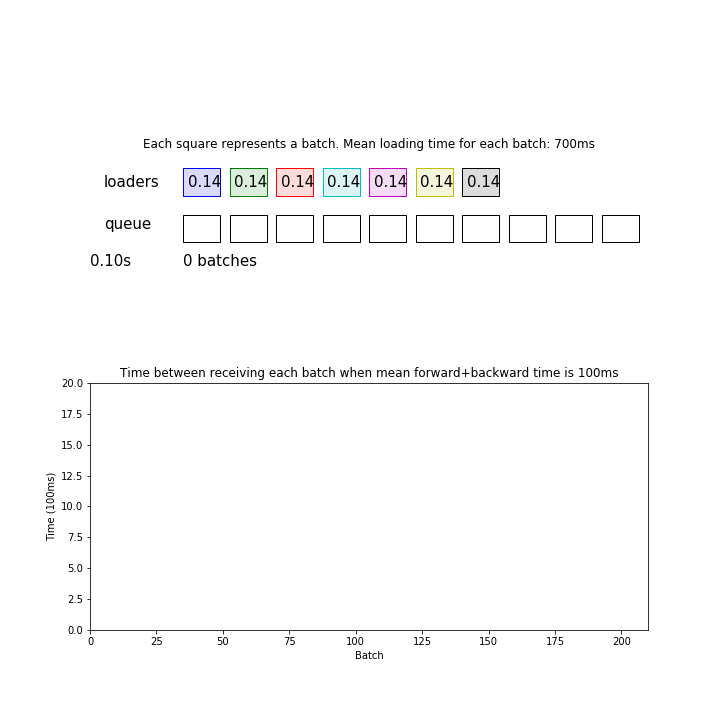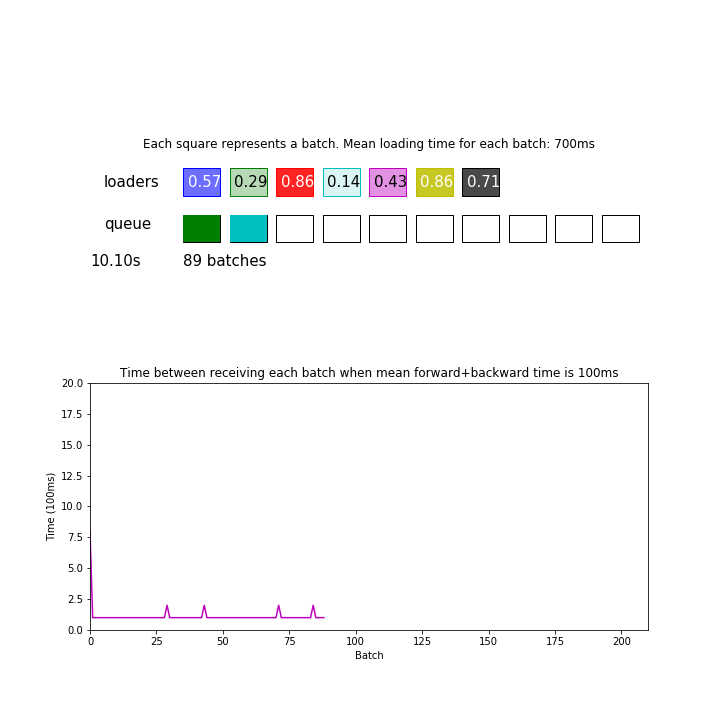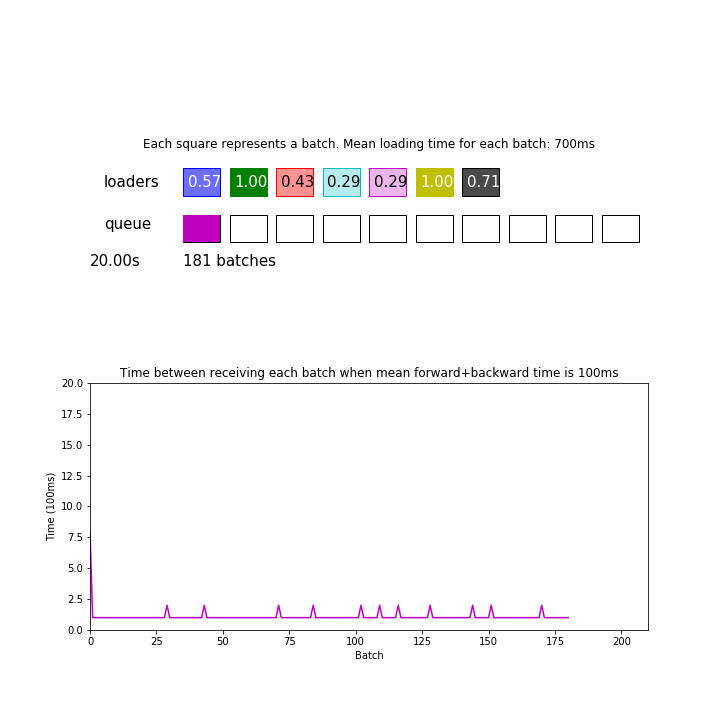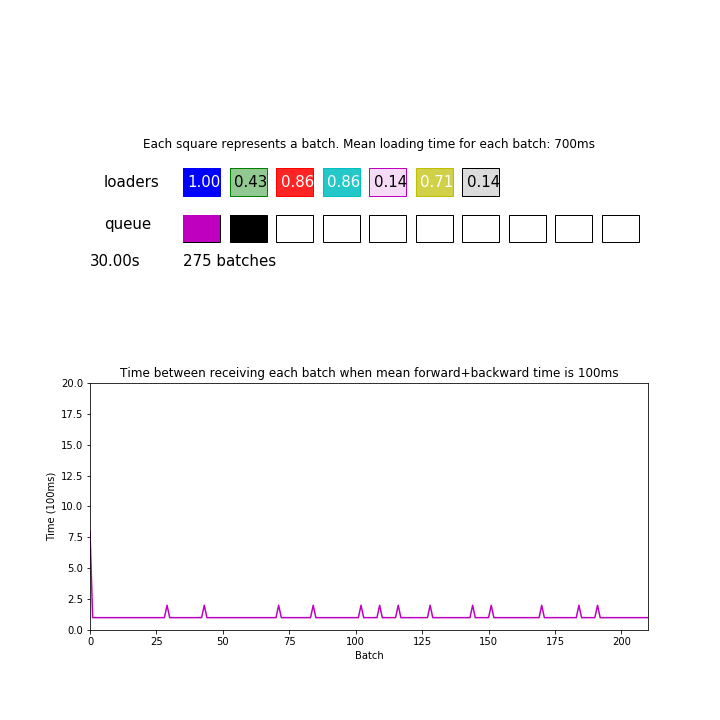
In the animation above, mean loading time for each batch is 700 ms. 700ms / 7 loaders is now matched with the consumption time of 100ms. This pipeline processed 275 batches during 30 seconds.
At this point, making the data loader more efficient will not speed up the training significantly, as shown in the following animation:
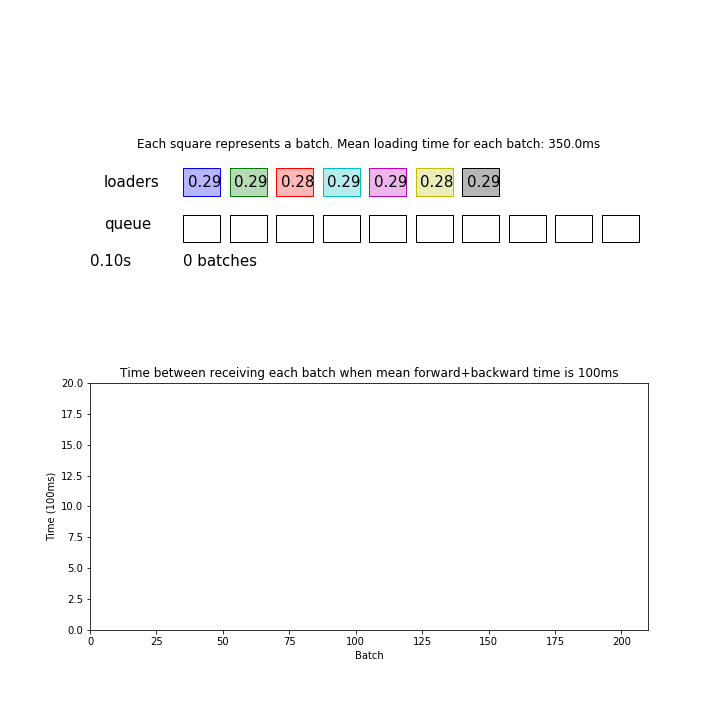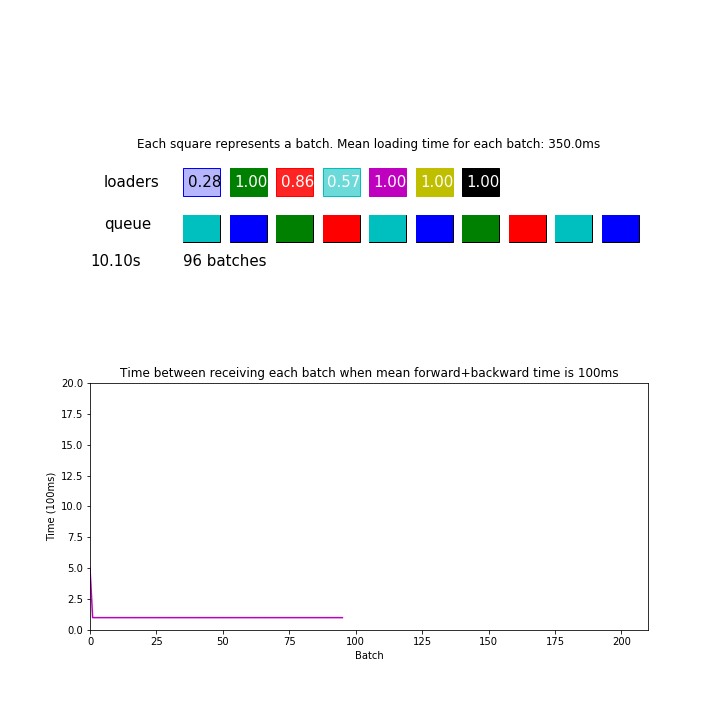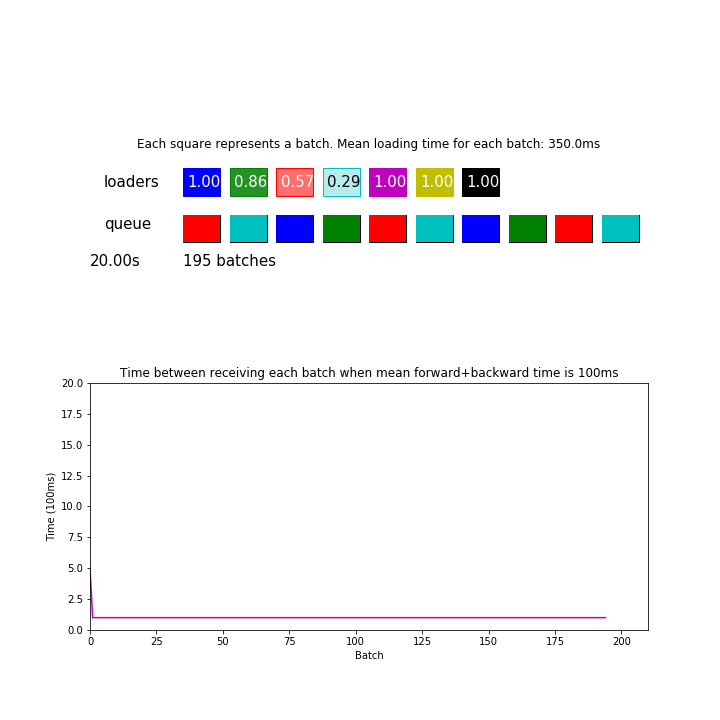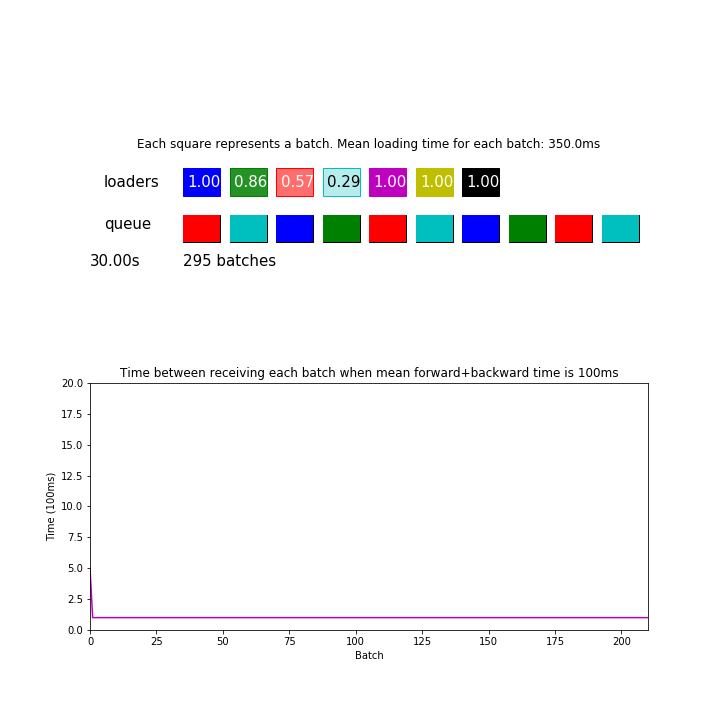
In the animation above, mean loading time for each batch is 350 ms, which is twice as faster as before. However, this pipeline processed 295 batches during 30 seconds which was only 7% more than before, basically just by making sure the queue is never empty when a model needs a batch.
You might think that your loader is fast enough when you don’t observe such regular spikes as shown in the first animation. But that is not the case. If your data loading time has high variance, or if your loaders are not so synchronized, you will no longer observe such halting even when your pipeline is still bottlenecked by data loading time:
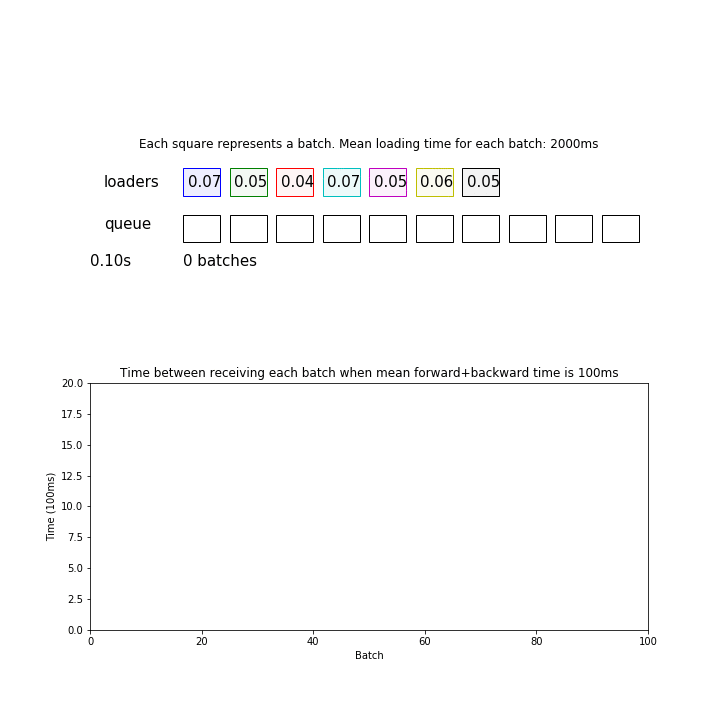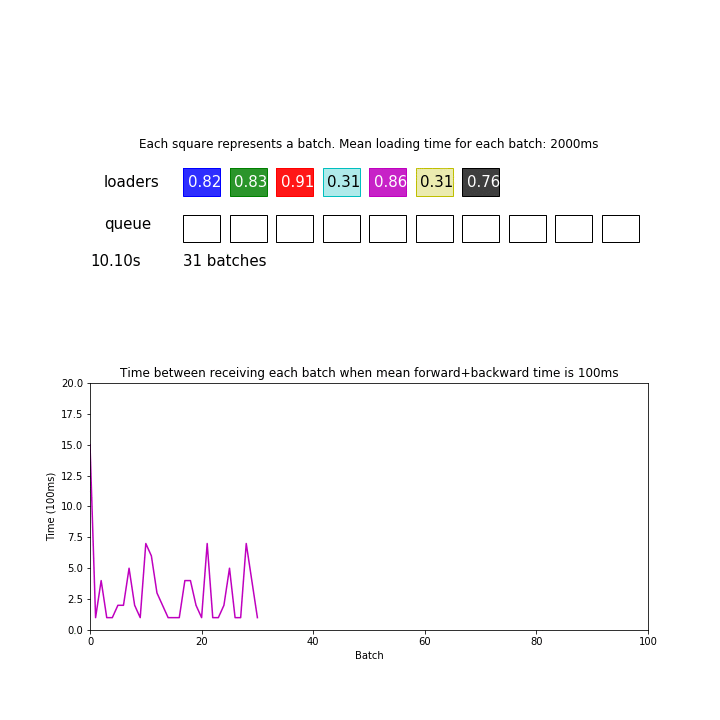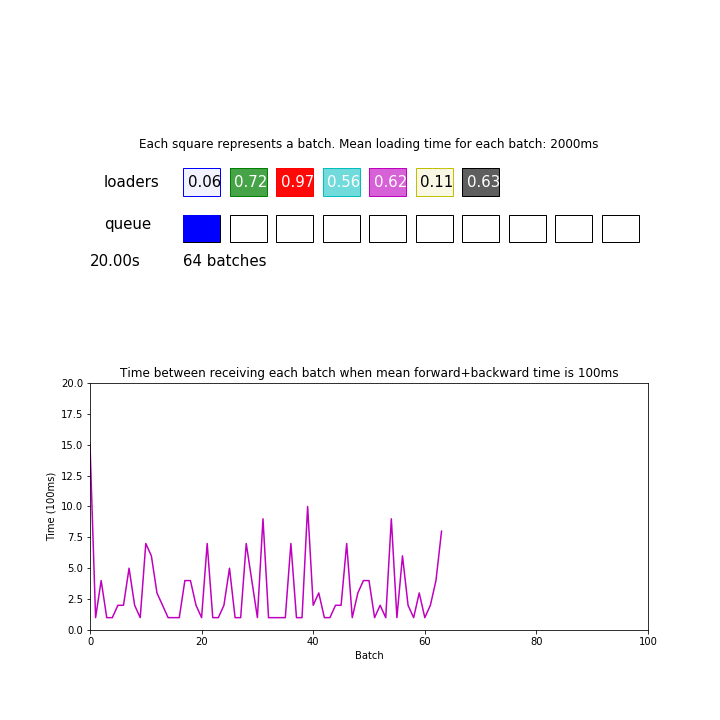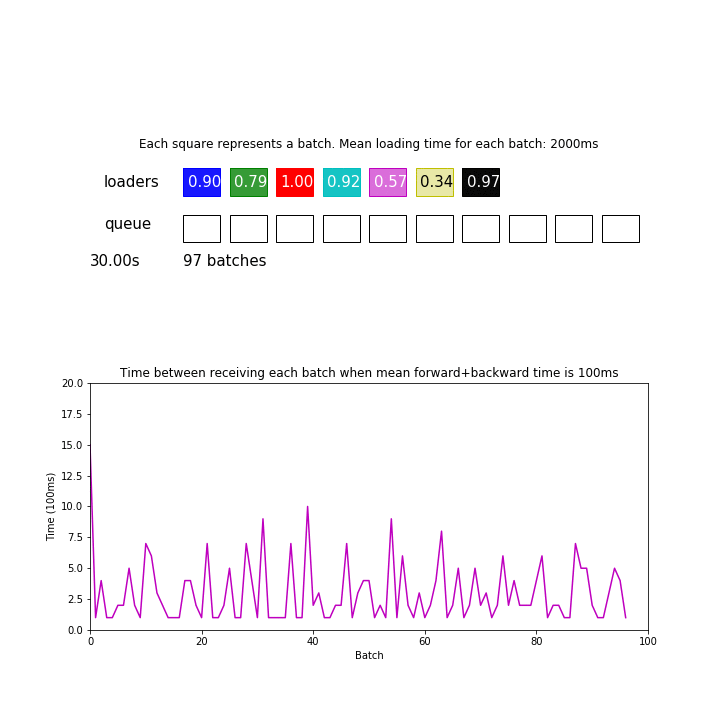
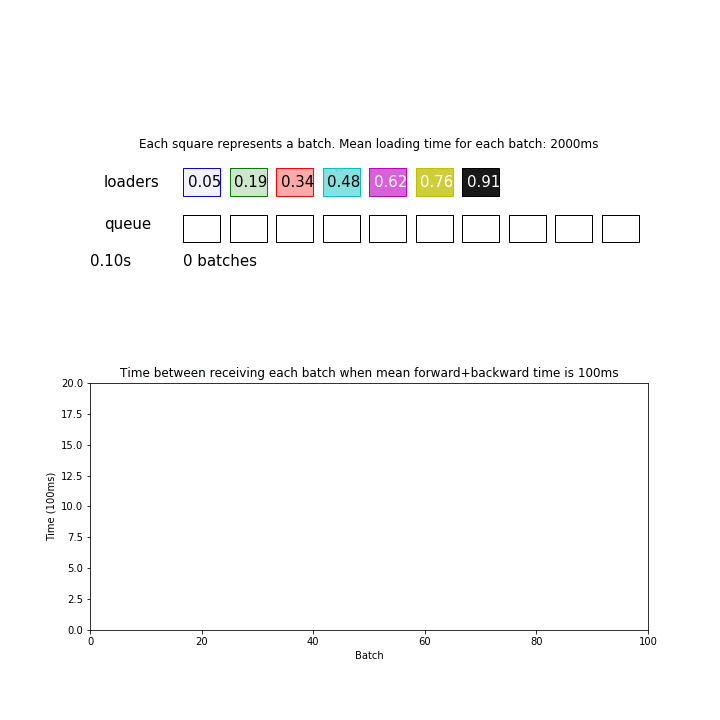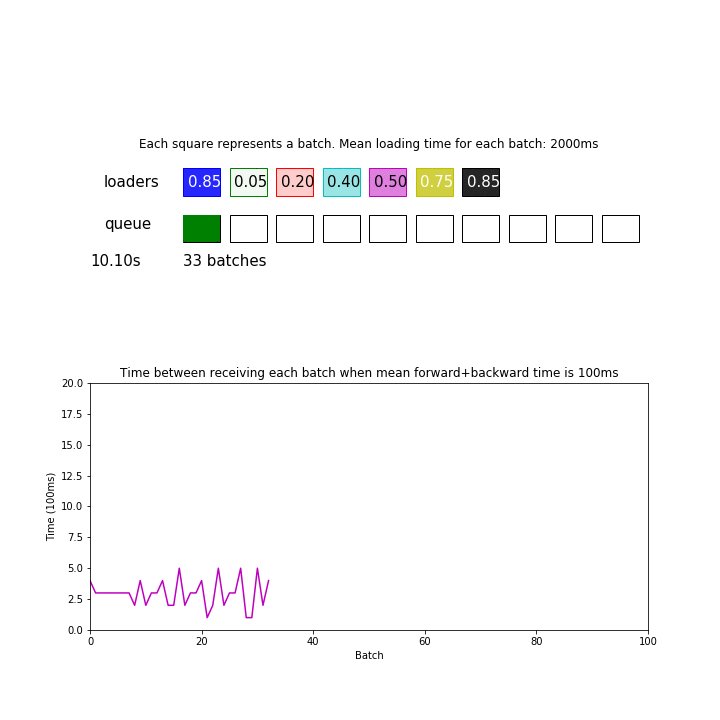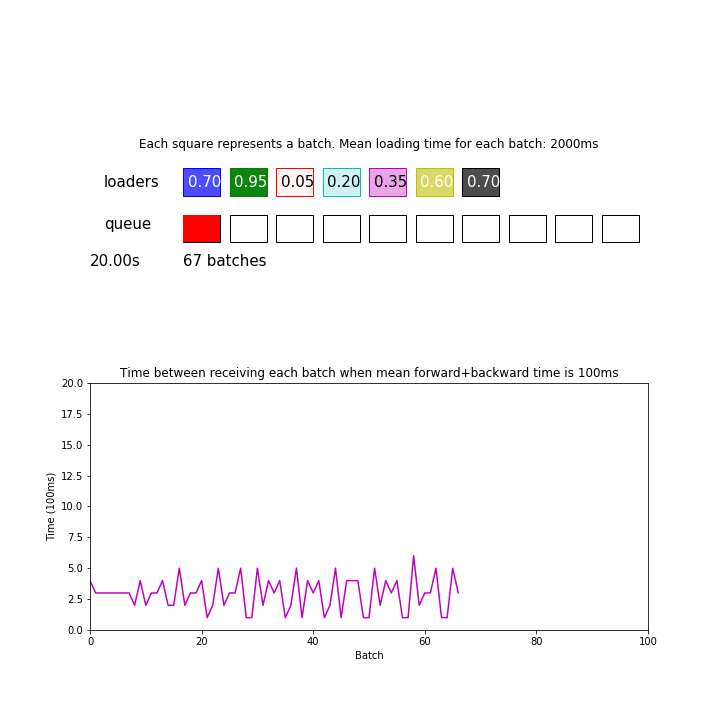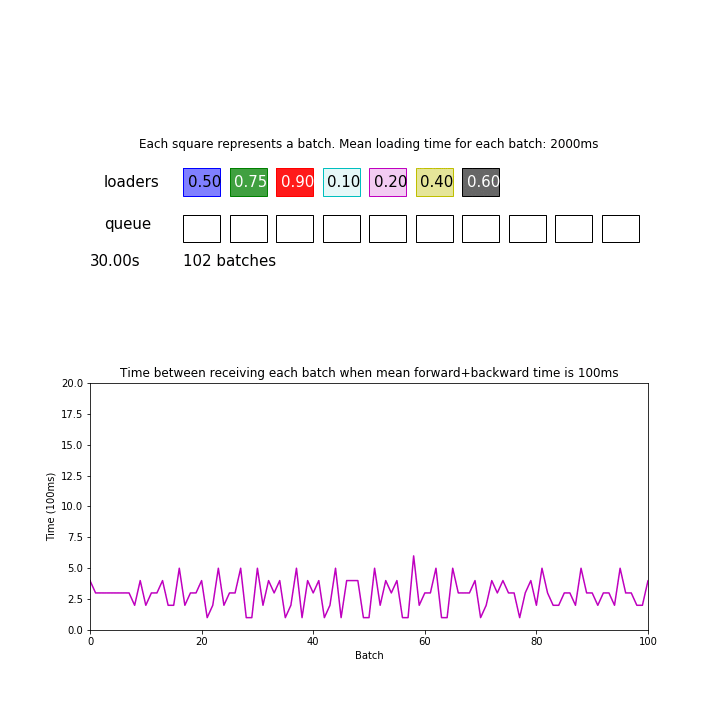
Thus, it can be important to actually measure your loading and forward/backward time to determine if you need a speedup.
Measuring time by inserting python code before and after an activity, however, might give you wrong estimates. CUDA operations such as forward/backward pass are asynchronous and you might take a measurement before the pass has actually finished. You can look at the following pages to mitigate this issue:
It’s not trivial to speed up your loading time other than just increasing the number of the loaders or decreasing the batch size. You need to do some data engineering work to avoid unnecessary memory copies, choose faster augmentation functions, and enable faster disk I/O. The following resources can be helpful:
- Data Engineering (e.g. faster disk I/O)
- Augmentation Libraries
More details about the visualizations
We can simulate and visualize a simplified version of the data loader and model training pipeline.
- Each loader process is represented as a cell in the “loaders” row.
- Each loader process is loading one batch at a time just like a PyTorch dataloader, rather than one example.
- It takes an average of x milliseconds to load a batch.
- The number represents the progress of loading the current batch (max=1), which is also represented by the alpha value of the cell color.
- Once the loading is complete, the loaded batch moves down to the data queue and is represented as the same color as the color of the loader process.
- The main process with a neural network loads one batch at a time from the queue, and performs forward/backward pass which takes an average of y milliseconds.
- The temporal resolution of this simulation is 100 milliseconds.
In this simulation, I am ignoring the following:
- the time it takes to send the data from loader process to the main process
- the time it takes to send the cpu tensor to gpu.
- variance in the forward/backward time of each batch