Can reinforcement learning agents generate and benefit from conventions when cooperating with each other in imperfect information game?
This is the question that led to my course project in “Advancing AI through cognitive science” course at NYU Center for Data Science. In summary, I applied theory-of-mind modeling to the Hanabi challenge [1] and observed an improvement.
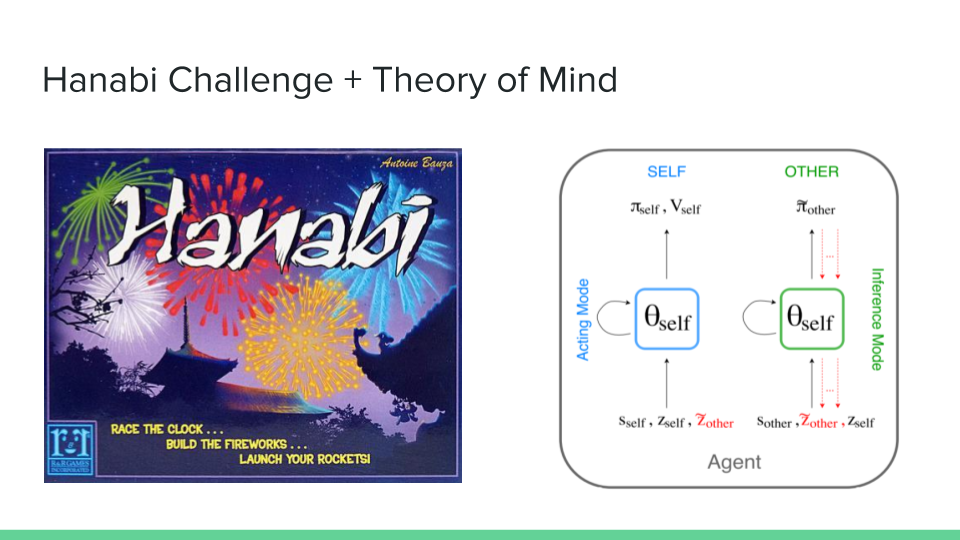
Applying Theory of Mind to the Hanabi Challenge
Hanabi is a card game created in 2010 which can be understood as cooperative solitaire. The common goal is to complete five decks of cards of different colors from number 1-5 in increasing order. What makes this game interesting is the fact that each player can see everyone else’s cards but not one’s own hand. Players can help each other figure out what their cards are by giving a limited amount of hints. You can learn more about it from the following video by Zamiell:
When humans play this game, it seems to be important to agree upon some conventions of custom rules in order to convey more information per hint as seen in Zamiell’s Hanabi Conventions. With help of conventions such as good touch principle (hint only the cards that will eventually be played), save principle (save all 5’s), chop, finesse and prompt, each player can convey more specific information via hint such as playing, discarding, or save a particular card.
I attempted to encourage the autonomous agents to come up with similar conventions by the applying some combinations of the following modifications:
- Share model weights for all agents in the game.
- Then everyone will always act in the same way.
- Modify the action space so that they output which specific card to give hints to rather than what type of hint to give to
- So that the agent has some explicit intention behind the hints.
- Apply Self-Other model [2] to infer the intention behind hints of the agents as well as estimates for the current agent’s cards based on other agents’ actions in the previous round.
- These estimates will be extra input parameters to the model of each agent.
With an approach I called input_SoM and reduced max replay buffer size, I observed a performance of 21.29 which is higher than both the best performance of vanilla rainbow agent I observed (20.54) and mean performance of the reported rainbow agent (20.64) in 2-player game of Hanabi.
If you are interested in learning more, you can see my github repo and the project paper.
References
[1] The Hanabi Challenge: A New Frontier for AI Research. Nolan Bard, Jakob N. Foerster, Sarath Chandar, Neil Burch, Marc Lanctot, H. Francis Song, Emilio Parisotto, Vincent Dumoulin, Subhodeep Moitra, Edward Hughes, Iain Dunning, Shibl Mourad, Hugo Larochelle, Marc G. Bellemare and Michael Bowling. arXiv:1902.00506, 2019.
[2] Modeling Others using Oneself in Multi-Agent Reinforcement Learning. Roberta Raileanu, Emily Denton, Arthur Szlam and Rob Fergus. arXiv:1802.09640, 2018.