Data Prefetching in Deep Learning
In the previous post I explained that, after a certain point, improving efficiency of the data loaders or increasing the number of data loaders have a marginal impact on the training speed of deep learning.
Today I will explain a method that can further speed up your training, provided that you already achieved sufficient data loading efficiency.
Typical training pipeline
In a typical deep learning pipeline, one must load the batch data from CPU to GPU before the model can be trained on that batch. This is typically done in sequence, and this device-transfer time is added to your overall training time.
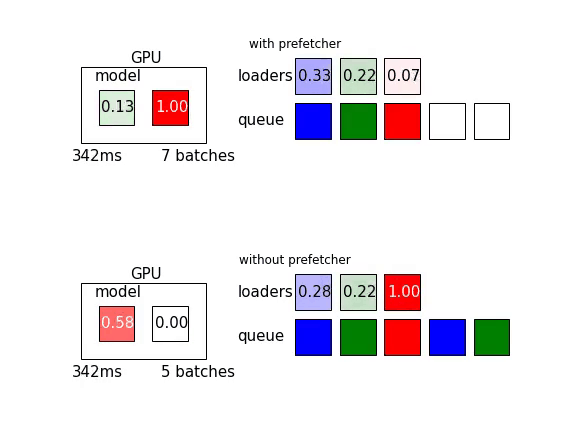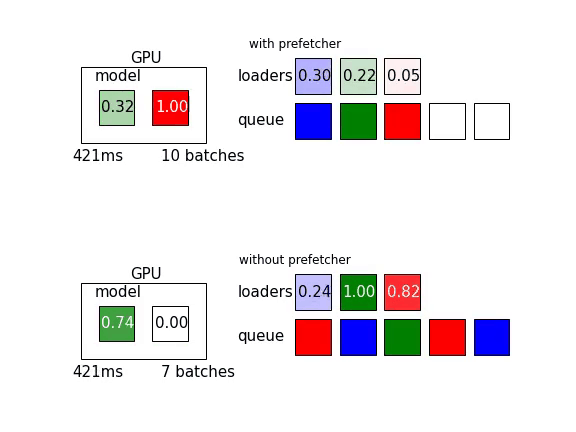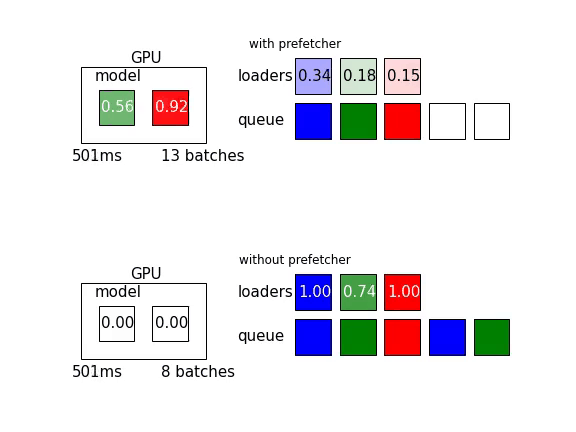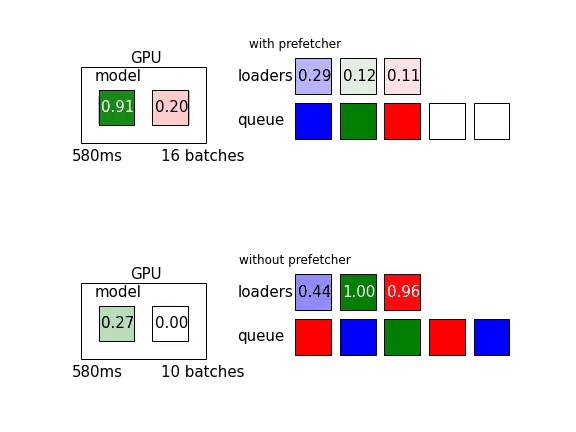
Mean loading time of one batch in CPU for each loader process is 80 ms, mean transfer time from cpu to gpu is 15 ms, and mean model time (forward+backward pass) is 30 ms.
As you can see, the CPU tensor is loaded to GPU memory and then processed by the model in sequence. This pipeline processed 20 batches during the first second.
Data Prefetcher
It is possible to further parallelize this pipeline. The data for the next batch can be loaded to GPU while the model is working on the current batch. The component that fetches the data in parallel is called data prefetcher. In ideal cases, the model can continue to train on data with 0 delays between batches.
With the same loading and transfer times, this pipeline with extra parallelization can process more batches during the same time. This pipeline processed 29 batches during the first second, which is 45% more than without the prefetcher.
Caveat
To be able to benefit from data prefetcher, the CPU-side data loader must be efficient enough. If the queue is empty while the model is processing the current batch, the prefetcher cannot work in parallel.
Mean loading time of one batch in CPU for each loader process is 160 ms, mean transfer time from cpu to gpu is 15 ms, and mean model time (forward+backward pass) is 30 ms. As you can see, if the training pipeline is already bottlenecked by the CPU-side loaders, there is little data prefetcher can do. This pipeline processed 17 batches during the first second while the counterpart without a prefetcher processed 16 batches.
In addition, using data prefetcher means you will need some extra VRAM to store another batch of tensors in GPU. If you were already maxing out the GPU memory, you won’t be able to use data prefetcher unless you change the model or the batch size.
Implementation
Data prefetcher can be used by pinning the CPU tensor (i.e. the pytorch dataloader should use the argument pin_memory=True) and setting non_blocking=True in .cuda() call as shown in this working version of data prefetcher in Apex project.
Links:
- Pinned memory buffers: https://pytorch.org/docs/stable/notes/cuda.html#cuda-memory-pinning
- Usage of custom pin_memory method: https://pytorch.org/docs/stable/data.html#memory-pinning
- Pytorch multiprocessing best practices: https://pytorch.org/docs/stable/notes/multiprocessing.html
- Useful discussions:
More details about the visualizations
- Each loader process is represented as a cell in the “loaders” row.
- Each loader process is loading one batch at a time just like a PyTorch dataloader, rather than one example.
- It takes an average of x milliseconds to load a batch.
- The number represents the progress of loading the current batch (max=1), which is also represented by the alpha value of the cell color.
- Once the loading is complete, the loaded batch moves down to the data queue and is represented as the same color as the color of the loader process.
- The main process with a neural network loads one batch at a time from the queue.
- The batch first gets moved to GPU memory
- This is represented as the second cell in the rectangle representing GPU
- Progress of 1 means the data is moved completely to GPU
- And then it performs forward/backward pass which takes an average of y milliseconds.
- This is represented as the first cell in the rectangle representing GPU (under “model”)
- Progress of 0 means the data is completely consumed.
- The batch first gets moved to GPU memory
- Compared to the previous blog post where the simulation depended on the temporal resolution (frame rate), the simulation in this blog post is performed event-based using simpy and therefore contains accurate result which do not depend on frame rate of animation.
- I am ignoring the time it takes to send cpu tensors between processes.
Disclaimer
This post is irrelevant to the prefetch_factor parameter of PyTorch DataLoader class. The prefetch_factor parameter only controls CPU-side loading of the parallel data loader processes. (According to PyTorch documentation, this parameter controls the number of samples loaded in advance by each worker. 2 means there will be a total of 2 * num_workers samples prefetched across all workers.)